Una semana antes del ballotage en la Ciudad de Buenos Aires que ganó Horacio Rodríguez Larreta, las encuestas estaban en todas partes, y los encuestadores aparecían por todos lados pronosticando, analizando e interpretando la situación política a partir de la lectura de sus trabajos de campo. Ello cambió en un santiamén. Las encuestas cayeron en desgracia y se sospecha no solo que no sirven, sino que se manipulan para distorsionar el proceso electoral. Este repentino cambio social no es nuevo en Argentina lamentablemente. No intentaré explicarlo pues no poseo justificación alguna para esta conducta social que, como mínimo, es descomedida. En cambio, trataré de explicar cuál es el alcance de una encuesta, qué tipos de errores pueden cometerse al realizarlas, y por último, mostraré que las encuestas de este último ballotage, no merecen estar bajo sospecha. No solo ello, diré también que es posible encontrar encuestas bien hechas en Argentina.
Inferencia a partir de muestras estadísticas
Inferir significa sacar conclusiones. La inferencia estadística nos proporciona métodos para sacar conclusiones a partir de datos. Lo nuevo de la inferencia es que utilizamos la teoría de la probabilidad para expresar nuestra confianza en las estimaciones que realizamos. La inferencia estadística es el proceso mediante el cual adquirimos información sobre una población a partir de una muestra. Cuando utilizamos la inferencia estadística, estamos procediendo como si los datos proviniesen de una muestra aleatoria o de un experimento aleatorizado. Si esto no es cierto, nuestras conclusiones pueden estar expuestas a cualquier tipo de objeción.
Consideremos una población sobre la cual deseamos estimar un parámetro, por ejemplo, la proporción que votará al PRO, sobre la base de una muestra estadística. Hay dos tipos de estimadores: a) estimadores puntuales y b) estimadores de intervalos. El estimador puntual infiere sobre la población estimando el valor de un parámetro desconocido en forma puntual, esto es, dándonos un único valor como estimación de dicho parámetro de interés. Ilustramos esto en la Figura I.
Figura I
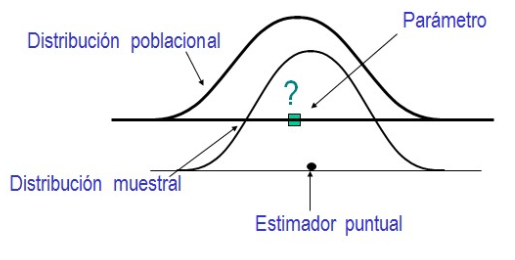
Un intervalo provee un conjunto de valores posibles sobre un parámetro poblacional desconocido. Un intervalo de confianza consta de dos componentes: a) un intervalo calculado a partir de los datos y b) un nivel de confianza asociado al mismo, el cual típicamente se fija en 95%. Ilustramos esto en la Figura II.
Figura II
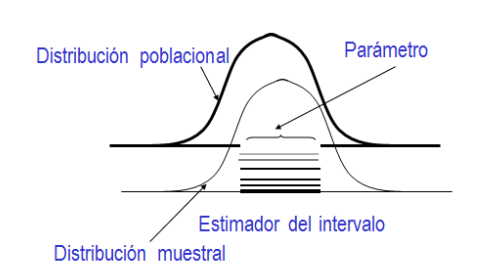
Así, por ejemplo, utilizando una muestra estadística, podríamos decir que la intención de voto al PRO es de 55 puntos porcentuales, con un intervalo de confianza de ± 3 puntos porcentuales, lo cual significa que utilizando nuestra muestra, con una determinada confianza, la verdadera intención de voto al PRO se ubicaría entre 52 y 58 puntos. Denominemos a estos 3 puntos el error de estimación muestral (el cual, en la jerga de las encuestas electorales, suele llamarse margen de error. Puede ser menor a 3 puntos y los medios de comunicación deben reportarlo para cada proyección). Existe un trade-off entre el nivel de confianza y el error de estimación. Para los mismos datos, un error de estimación menor requiere que aceptemos un nivel de confianza menor. Asimismo, es más fácil estimar un parámetro con precisión cuanto menor es la varianza de los datos poblacionales. Debido a esto último, un incremento del tamaño de la muestra reduce el error de estimación para un nivel de confianza determinado. Entonces, si queremos reducir el error de estimación, debemos tomar muestras más grandes. En el límite, si tomamos como muestra a toda la población, no tendremos error de estimación alguno.
Error total de una encuesta
Dificultades prácticas, tales como la no-respuesta o la falta de cobertura de una encuesta, pueden causar errores adicionales que podrían ser mayores que el error proveniente del muestreo aleatorio. Una encuesta producirá mejores resultados si logra evitar los cuatro tipos de errores presentados en la Figura III.
Figura III
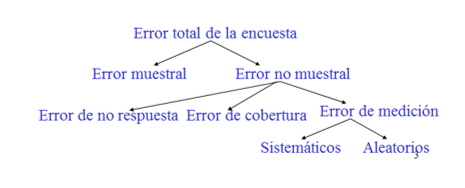
Como ya vimos, el error de muestreo se puede controlar aumentando el tamaño de la muestra. Mientras que los errores no muestrales (de diseño) no pueden reducirse aumentando el tamaño muestral. Así, por ejemplo, si un grupo de votantes de izquierda dice que votará en blanco, pero en realidad no lo hace y vota a algún otro partido, este error de medición sistemático sesgará la estimación realizada a partir de la muestra estadística.
Finalmente, también hay que saber que entre el momento que se hace una encuesta y el día de la votación, generalmente, pasa un tiempo, quizás hasta una semana. En esa semana, no solo los indecisos terminan decidiendo su voto, sino que también, cambios en la opinión pública pueden alterar el voto de muchos otros ciudadanos.
Ballotage
Una semana antes del ballotage en CABA, la consultora Poliarquía, para el diario La Nación, proyectaba que Rodríguez Larreta obtendría 55,3% de los votos, contra 44,7% que irían para Lousteau. Estos resultados, y otros similares, fueron luego fuertemente criticados. Sin embargo, si uno los analiza cuidadosamente, no fueron tan errados. Rodríguez Larreta obtuvo finalmente 3.7 puntos menos que los arrojados por esa proyección, apenas un poco por arriba de un margen de error de 3 puntos. Por ejemplo, la misma consultora, también para el diario La Nación, pronosticó que en el ballotage de 2007, en CABA, Macri obtendría el 57.1% de los votos, contra un 42.9% que irían para Filmus. Los resultados finales fueron 60.9% contra 39.1%.
Me parece claro que el principal problema en el último ballotage fue que se puso todo el énfasis en la diferencia entre los candidatos, pues ello importaba para las PASO mientras que en el pasado, ello importó menos. Lamentablemente, y especialmente en un ballotage, donde los errores muestrales entre ambos candidatos están fuertemente correlacionados, medir la diferencia de votos con la misma precisión que el nivel de votos de cada candidato requiere muestras más grandes. Sin embargo, no creo que esto sea todo lo que ocurrió, pues es raro que la gran mayoría de las proyecciones de la diferencia de votos entre ambos candidatos estuviese sobrestimada si solo se tratase de un error muestral. También hubo un error de medición. Se esperaba que 8% del electorado votase en blanco y solo lo hizo el 5%, por lo cual 3% de los electores votó a uno de los candidatos –seguramente a Lousteau. Asimismo, hubo también error de predicción por no respuesta. Se argumenta que se podría haber proyectado mejor el voto de los votantes indecisos, pero ello requiere un modelo de comportamiento, algo que excede el trabajo de una encuesta. Finalmente, pudo haber cierto error de “cobertura” por las vacaciones de invierno.
Nada de esto justifica la descalificación generalizada de las encuestas ni de las firmas que las realizan. A modo de ejemplo, Poliarquía, en su página web publicó un documento en el que resume 10 años de pronósticos realizados para el diario La Nación. En 17 elecciones, siempre predijo correctamente el ganador de la elección y el que ocupaba el segundo lugar. Además, el margen de error promedio de sus proyecciones fue 1.4 puntos porcentuales.
Conclusión
Seguramente, como en todas las áreas, entre las firmas encuestadoras hay alquimistas, científicas, y deshonestas. Sin embargo, los resultados del último ballotage solo justifican interpretar más cuidadosamente los resultados de las proyecciones, saber que el margen de error puede ser grande y que hay otras fuentes de error de diseño que muchas veces no pueden evitarse. Las encuestas bien hechas, aun con sus errores, son un instrumento muy útil en la toma de decisiones de los ciudadanos. Por supuesto, me parece una muy buena idea que se informe quien financió cada encuesta cuando estas se dan a conocer.



















{kind=link}
Esta encuesta de Jorge Giacobbe me resulta plausible. En las PASO Daniel Scioli, sin interna, 36,1 por ciento. En Cambiemos, Macri 29,35%; Elisa Carrió 1,6% y Ernesto Sanz 1,2%. En la interna de UNA, Massa 13,5% frente a De La Sota 4,6%. En la elección general, es la consultora que le da menor diferencia a Scioli (37,8%) sobre Macri (33,1%). Para Giacobbe, Massa no crece y se mantiene con 14,8%.
La Nación hoy publico la encuesta de Poliarquía para las PASO. Interesante pues da la impresión que se reportan distintas proyecciones de los indecisos, pero el diario no reporta el margen de error. De todas formas, los resultados son interesantes. Si se da el mejor escenario para Cambiemos, se proyectaría un escenario de ballotage. Scioli tendría 38 y Cambiemos 34% del electorado. Clarin publica una encuesta de Mora y Araujo que se acerca mucho a este escenario. Tambien informa sobre la de Giacobbe que menciona Paula arriba, la cual claramente sugiere que podría haber ballotage. Claramente, si Scioli llega a 41 puntos (el mejor escenario de Poliarquía), tiene chances de ganar en primera vuelta. Habrá que vivir en un país que elige en primera vuelta (o segunda, for that matter) a un gobernador que hace 7 años no presenta su declaración jurada.
Macri tendrá que salir a captar el voto de Stolbizer y del Massismo…
La izquierda, que podría llegar a 3 puntos, cuanta solamente si hay ballotage. No votara por Macri…
Pagni gasto 2 paginas hoy para decir esto!
Creo que la crítica más seria no apuntaba a una consultora, sino al hecho de que TODAS dieran mal para el mismo lado. Quizás debiste comentar sobre si eso es o no razonablemente probable. Me suena que no.
Me parece que lo hago. Justamente, debido a ello explico no solo el error muestral sino también el error total de una muestra. Luego digo: “Lamentablemente, y especialmente en un ballotage, donde los errores muestrales entre ambos candidatos están fuertemente correlacionados, medir la diferencia de votos con la misma precisión que el nivel de votos de cada candidato requiere muestras más grandes. Sin embargo, no creo que esto sea todo lo que ocurrió, pues es raro que la gran mayoría de las proyecciones de la diferencia de votos entre ambos candidatos estuviese sobrestimada si solo se tratase de un error muestral. También hubo un error de medición. Se esperaba que 8% del electorado votase en blanco y solo lo hizo 5% del mismo, por lo cual 3% de los electores votó a uno de los candidatos –seguramente a Lousteau. Asimismo, hubo también error de predicción por no respuesta. Se argumenta que se podría haber proyectado mejor el voto de los votantes indecisos, pero ello requiere un modelo de comportamiento, algo que excede el trabajo de una encuesta. Finalmente, pudo haber cierto error de “cobertura” por las vacaciones de invierno”
Sebastian, comparto con vos que la difusión de una encuesta debe incluir (por ejemplo), márgen de error y nivel deconfianza. Sin embargo noto sistemáticamente que se divulgan márgenes de error +-.3%, yo con mis conocimientos elementales de estadística recuerdo que elmárgen de error para una proporción (dado el nivel de confianza) depende de la magnitud de la proporción, es decir que el márgen es diferente para quien tenga 50% de intención de voto que para quien tenga 10%.Si tomamos el caso de las elecciones generales y suponiendo que alguna encuesta estimó exactamente el resultado; un margen de error +-3% para el PRO hubiese oscilado entre 42 y 48%, pero para Zamora entre 1% y 7%, en el primer caso sería un margen aceptable pero en el segundo una diferencia entre extremos del 600%.
Ergo creo que hay poco rigor en algunos casos; otro aspecto llamativo es que muchoas encuestas trabajan con el mismomargen de error,igual nivel de confianza pero TAMAÑOS DEMUESTRA DIFERENTE.Es raro.
Correcto: La varianza de una proporción depende de la misma y por tanto, como señaló en la entrada, entonces, también lo hace el error muestral. Cuanto mayor es la varianza, mayor es el error muestral, ceteris paribus. Por su puesto, una encuesta debe fijarse un objetivo y determinar el tamaño muestral en forma acorde. Claramente, para algunos candidatos, el error muestral será menor y para otros mayor. No creo que se justifique tener una muestra tan grande como para ser muy preciso con un candidato que apenas mide 2 puntos… No por ello la encuesta no es rigurosa. Es rigurosa y racional!!
Comparto lo que me decis; a lo que apunto es a dos cuestiones:1) la divulgación de las encuestas difunden un margen de error único para todos, y como bien me aclaras «Claramente, para algunos candidatos, el error muestral será menor y para otros mayor», esto es un déficit de la publicación y no de la encuesta.
2) Ante muestras de diferente tamaño la ficha técnica suele tener igual margen de error e igual nivel de confianza, y es eso lo que me parece raro y poco riguroso.
Igualmente comparto en que el déficit está en la manera en que se divulga que puede dar lugar a interpretaciones equivocadas de parte del lector,y no tanto en las encuesta propiamente dicha.
Nuevamente, mi punto no era “todas las encuestas están bien”. Solamente, hacer una encuesta es útil y no trivial. Hay fuentes de errores naturales. Sospechar de las encuestas por el ballotage de CABA es descomedido. Pero que se reporta mal, no tengo dudas. Una cosa que siempre me asombra es la facilidad con la que se confunden los puntos porcentuales por %. Es muy importante reportar bien la información científica. Por ello, en JPAL, desarrollamos un taller para periodistas que busca ayudar a mejorar la forma en que se reportan estas cuestiones. El 27 de Agosto, lo dictare en UTDT.
En una época, por ejemplo, cuando la EPH se hacía rigurosamente, el error muestral se fijaba para la tasa de desempleo. Sin embargo, con la EPH se estiman muchas otras variables, tales como la tasa de pobreza, el empleo, la desigualdad, etc. El desempleo era una buena variable, pues probablemente tenía una varianza mayor que estas otras variables también importantes.
Muchas veces el desempleo sube o baja 0.5 puntos porcentuales entre dos mediciones. Ello no puede distinguirse de la variación muestral. Nunca entendí las páginas de diario que se gastan para explicar por qué en tal caso subió o bajo el desempleo…
…Yo nunca entiendo cuando se titula que el escrutinio definitivo arroja un triple empate técnico (como en el caso de Santa Fe, este año), cuando el empate técnico está vinculado con el margen de error muestral, que es nulo cuando se contaron la totalidad de los votos.
Acá tenes una encuesta donde finalmente se reportan bien los resultados, con el margen de error para cada candidato. Creo que este post ha tenido algún impacto en la prensa. En buena hora! http://www.clarin.com/politica/Elecciones_2015-Sergio_Massa-Mauricio_Macri-Daniel_Scioli-encuestas-Cambiemos-Management_-_Fit_0_1408059199.html
Hago una pregunta que me inquieta un poco. Escuché que es común el comportamiento de «votar al que viene ganando según las encuestas» de manera de capitalizar como votante, el triunfo. Más allá de lo poco racional que me parece este comportamiento, de existir y estar lo suficientemente generalizado, puede complicar bastante la predicción, y habría que predecir el número de votantes sabiendo cuántos se van a ir/votar al mayoritario una vez que publiquemos las encuestas. Le parece plausible esto?
Elección sin sorpresas a nivel nacional, dadas las encuestas:
http://www.lanacion.com.ar/1817950-esta-vez-las-encuestadoras-acertaron-en-los-pronosticos-de-las-paso
Unos comentarios sobre las encuestas de este domingo. Claramente, las encuestadoras predijeron mucho mejor el voto a Scioli y Massa que a Macri, lo cual es consistente con la evidencia que presenta Elypsis sobre un fuerte aumento en el porcentaje de votos a Macri durante los últimos días previos a la elección. Nada que hacer sobre esto a menos que uno pueda medir los días previos (y por ley no se pueden publicar encuestas 8 días antes de una elección …).
Relacionado, unas encuestas que vi en detalle, de la primer semana de Octubre, predecían mucho mejor el voto si uno no toma en cuenta la extrapolación que hacían entonces de los indecisos. Insisto, nuevamente, las firmas encuestadoras no usan –ni tienen- buenos modelos para hacer ese ejercicio no entiendo por qué insisten en hacerlo.
Creo que no se investiga sistemáticamente estas cuestiones. Por ejemplo, ¿no se esperaba el repunte de Macri en CABA?
Encuesta de Poliarquía de esta semana le da 8 puntos de ventaja a Macri, pero con un margen de error de 3.5 puntos, que en un caso extremo, podría poner a ambos candidatos en situación de paridad. Además, hay 6 % del electorado indeciso, y 4% que votaría en blanco. Falta además el debate, y por ley, no habrá encuestas públicas luego del mismo…
Me cuentan encuestas electorales realizadas desde cuentas en Twitter. ¿Cuál es el valor de estas encuestas? Ninguno. Ni siquiera tendría valor aun si la población objetivo fuese la población de Twitter pues no habría un proceso de asignación aleatoria de la muestra. Solo responderán aquello que siguen a la cuenta de quien hace la encuesta, y ni siquiera lo harán de forma que represente a estos seguidores. Contestan los que ven la encuesta y tienen ganas de contestar…
Aun si una de estas encuestas le pega al resultado, no tiene valor. Es simplemente una casualidad. Yo tengo un reloj que no funciona y dos veces por día igual me da la hora exacta. La validez de una encuesta esta en su metodología, no en el resultado.