En Colombia, como en muchos otros países, las encuestas de hogares son la fuente de información básica para calcular los indicadores sociales más importantes, como son la incidencia de la pobreza y el coeficiente Gini de desigualdad, e indicadores laborales como las tasas de participación y de desempleo.
Como las encuestas son mensuales, la incidencia de la pobreza en un año cualquiera se calcula como el promedio de las tasas de pobreza mensuales de ese año. La pobreza mensual es el porcentaje de personas que pertenecen a hogares que, en el mes de referencia, tuvieron un ingreso per cápita inferior a la línea de pobreza mensual, definida para la ciudad o región correspondiente. En el año completo 2019, en Colombia, el porcentaje de personas clasificadas como pobres respecto al total de la población nacional fue 35,7%, según el DANE. De forma semejante se calcula la brecha de pobreza, que en 2019 fue 13,9%. La brecha de pobreza es la diferencia porcentual entre el ingreso de cada persona catalogada como pobre y la línea de pobreza.
¿Qué podrían tener de mal estos cálculos? Pues, sencillamente que no son anuales, sino promedios de datos mensuales. Esto no sería un problema si las encuestas fueran un panel de hogares representativos de todos los hogares, o si las encuestas de corte transversal preguntaran a todos los individuos –ocupados, desempleados e inactivos— los ingresos laborales obtenidos durante los últimos 12 meses. En este caso no aparecería como pobre (anual), una familia que es pobre seis meses pero que los otros seis meses gana más que suficiente para compensar su brecha de pobreza de los seis meses malos. Pero como las encuestas no son de panel sino de corte transversal —y dado que los ingresos laborales corresponden únicamente al mes de referencia de la encuesta—la familia que se observa un mes bajo la línea de pobreza cuenta como un doceavo de familia pobre para los cálculos anuales. Y eso está mal, porque una cosa es ser pobre un mes y otra serlo un año. Las dos medidas coinciden únicamente para las familias cuya probabilidad de ser pobres un mes cualquiera es 100%. Si la probabilidad es menor, entonces hay menos “pobres anuales” que el promedio de pobres mensuales.
Para mi sorpresa, este asunto tan básico ha sido ignorado por los estudiosos de la pobreza, no solo en Colombia sino, hasta donde tengo conocimiento, en todos los países que usan encuestas de corte transversal.
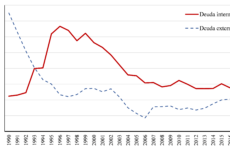
Pero el abuso de las encuestas de hogares (de corte transversal) no para ahí. Igualmente se utilizan para calcular la desigualdad. Supóngase que los hombres tienen trabajos remunerados 12 meses al año, pero las mujeres sólo tienen trabajos remunerados seis meses al año. Para simplificar la historia, supóngase que todo el mundo gana el mismo salario mensual. Obviamente, con los datos mensuales no hay desigualdad salarial, mientras que con los datos anuales sí. Por consiguiente, cuando se habla del Gini de desigualdad debería especificarse si se trata del Gini mensual (promedio del año) o del Gini anual, porque son cosas muy distintas. Según mis cálculos, para los ingresos laborales en Colombia, la diferencia entre un Gini y el otro son unos 10 puntos porcentuales. Nada despreciable.
Los problemas no paran ahí. Las tasas de participación y desempleo también se calculan regularmente con datos de encuestas de hogares de corte transversal. Supóngase que todas las mujeres dejan su trabajo remunerado tres meses al año para dedicarse a tareas del hogar. Por consiguiente, su tasa de participación, de la forma como usualmente se calcula, es 75%. Pero, en realidad, su tasa de participación anual es 100%, sólo que participan con una intensidad del 75%. Son enormes las implicaciones prácticas y de política de una u otra interpretación.
Esto es más claro aún en el caso del desempleo. Si todo el mundo cambiara de empleo una vez al año, y si tomara en promedio 5,2 semanas encontrar un empleo nuevo, la tasa de desempleo calculada de la forma usual sería 10% y el fenómeno afectaría al 100% de los trabajadores. También la tasa de desempleo sería 10% si uno de cada 10 trabajadores nunca logra conseguir empleo (y se mantiene en la búsqueda) mientras que nueve de cada 10 trabajadores siempre tienen empleo (y nunca tienen que buscar). Reconociendo que es así, se acepta que la tasa de desempleo es el producto de la tasa de incidencia del desempleo por la duración promedia del desempleo. Lo curioso es que un concepto semejante no se use para otras medidas laborales y sociales como las mencionadas en este artículo.
Con Miguel Benítez y Diego Gutiérrez, investigadores de Fedesarrollo, estamos trabajando en un documento técnico para precisar el problema y proponer metodologías de análisis retrospectivo y de recolección futura de los datos que permitan corregirlo. Creemos que son muchas las implicaciones de política. Sin ir más lejos, de indicadores como estos depende la asignación de los subsidios y el debate sobre la incidencia del IVA y del impuesto de renta de las personas.
Bienvenidas las reacciones y sugerencias de otros investigadores y hacedores de política.